Дата: 28 декабря 2022
Line
В период с сентября 2023 года по декабрь 2023 года Ассоциации Больших Данных совместно с компанией HFLabs проводила тестирование кейса «Защита банковской информации». В рамках этого тестирования была отработана серия атак на данные, имитирующие банковский анализ оттока клиентов (Churn-анализ Churn ), защищенный с помощью продукта HFLabs «МАСКИРОВЩИК». Особое внимание уделялось атакам с использованием «ранее утекших» наборов данных.
Примечание
Угрозы обезличенным данным являются одним из самых серьезных факторов, существенно ослабляющих существующие средства защиты.
Рекомендация
Фокусироваться на мерах снижения рисков выделения, чтобы минимизировать общие риски безопасности данных.
Рекомендация
Чтобы предоставить каждому пользователю разрешение на создание новых проектов, создайте новый Автоматическое назначение команд для команды «Создатели проекта».
Подсказка
Чтобы предоставить каждому пользователю разрешение на создание новых проектов, создайте новый Автоматическое назначение команд для команды «Создатели проекта».
Некоторые графики, иллюстрирующие результаты тестирования, приведены ниже.
Карта вероятности повторной идентификации
Выбраны квази-индентифиаторы: пол, регион, диапазон возраста. Ниже представлена карта повторной идентифиации
152 записи из 2190 имеют значение k=1, то есть легко идентифицируемы под воздействием атак выделения
Данная группа методов реализует подход, при котором формируется безопасная среда хранения и обработки данных в организации-операторе данных. Такие методы помогают снижать риски нарушения конфиденциальности данных за счет организационных и технических мер:
Наличия документированных процедур обработки персональных данных;
Подготовки и обучения персонала, имеющего доступ к законно обрабатываемой информации
Защиты метаинформации (данных, характеризующих профиль информации), которая может помочь злоумышленникам в организации атак на персональные данные.
Защита хранения данных (без учета их публикации), которая позволяет предотвратить утечки информации и прямое или косвенное (за счет появления дополнительных сведений) раскрытие конфиденциальной информации.
Учет контекстных рисков осуществляется за счет скоринга принимаемых мер, который формирует фактор-множитель, снижающий или увеличивающий риски данных (непосредственно передаваемой/раскрываемой информации):
Блок-схема:
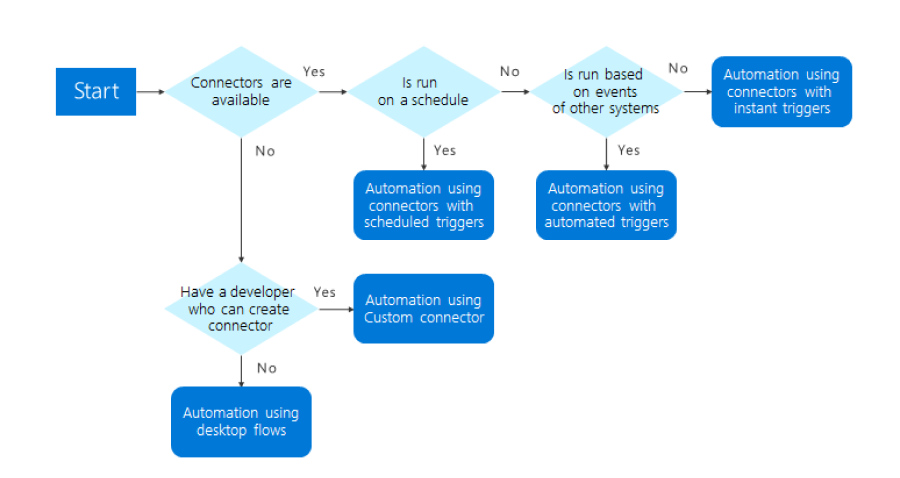
Использование контекстных методов защиты позволяет несколько снизить общие риски защиты информации, однако передаваемые исходные данные, содержащие персональные сведения, являются автономным носителем информации и получение к ним доступа несет риски для конфиденциальност и физических лиц. В связи с этим выделяются методы защиты данных и связанные с ними риски защиты данных (то есть риски на основании самих данных без учета контекста).
Структурно данные о физических лицах можно представить в виде набора, определяемого своей структурой (атрибутами, полями или столбцами), в каждой строке которого (отдельной записи) содержится информация об отдельном физическом лице. С информационной точки зрения атрибуты можно разделить на:
Прямые идентификаторы - то есть поля, прямо указывающие на конкретное физическое лицо). К таким атрибутам относятся, например, номера телефонов, электронная почта, номер и серия паспорта, в некоторых случаях (для ограниченной группы) – фамилия имя и год рождения. В качестве прямого идентификатора может также выступать любая строка, однозначно указывающая на физическое лицо;
Косвенные идентификаторы (квази-идентификаторы) - атрибуты в совокупности позволяющие выделить из группы лиц, описываемой набором информации отдельное физическое лицо. Примером косвенных идентификаторов является, например, совокупность возраста, пола и размера зарплаты;
Чувствительные атрибуты – поля, содержащие полезную (изучаемую) информацию, ради которой набор создается и публикуется (передается в рамках информационного обмена).
Методы псевдонимизации – методы защиты персональных данных, при которых прямые и/или косвенные атрибуты в конкретных наборах данных заменяются на один или несколько искусственных идентификаторов.
\(P_{повторной~идентификации} = P_{контекстные~риски} \times P_{риски~данных}~~\#(1)\)
Учет контекстных рисков осуществляется за счет скоринга принимаемых мер, который формирует фактор-множитель, снижающий или увеличивающий риски данных (непосредственно передаваемой/раскрываемой информации):
\(P_{контекстные~риски} = \frac {\displaystyle\sum_{j=1}^{n} w_{j} K_{j} } {\displaystyle\sum_{j=1}^{n} w_{j} }~~\#(2)\)
Учет контекстных рисков осуществляется за счет скоринга принимаемых мер, который формирует фактор-множитель, снижающий или увеличивающий риски данных (непосредственно передаваемой/раскрываемой информации).
 Главная
Главная